
南京大学章宗长俞扬&腾讯叶德珩团队 投稿
量子位 | 公众号 QbitAI
在经典RL流程里,智能体只有在撞了南墙、遍历海量状态后,才能慢慢学到怎么完成任务,样本效率极低。过去也有人引入大模型提示,但通常每换一个任务就得重新写prompt、再调一次API,既贵又难迁移。
来自南京大学章宗长俞扬团队和腾讯叶德珩团队的研究者们注意到,GPT这类大模型已经内化了大量日常常识,如果能一次性让它总结出“在这个环境下普遍有用的行为准则”,那么后续所有任务都可以共享同一份知识,省去反复调用。

背景知识是怎么“炼”出来的?
什么是“环境背景知识”? 通俗来说,就是对整个环境有用的常识,而不局限于某个具体任务。
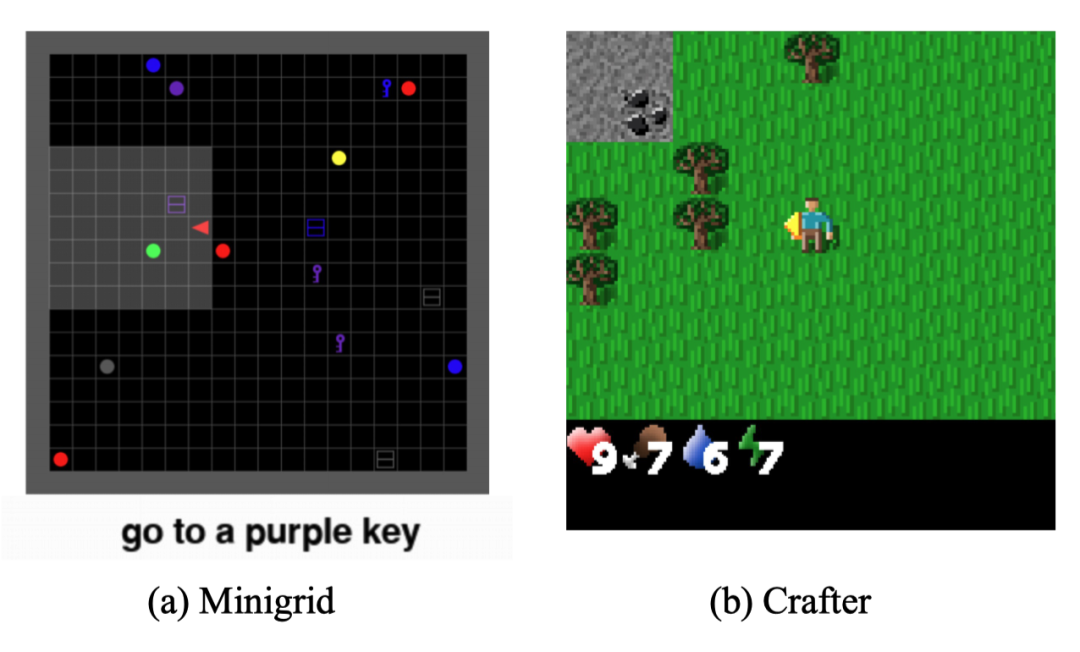
例如在迷宫类环境中“不要碰墙壁,绕开障碍物”,在生存游戏中“优先捡取食物保持存活”等经验,都属于对该环境通用有益的知识。有了这些知识,智能体在执行任何特定任务时都能更有效率地探索。

研究者用RND算法在环境里进行随机探索和学习,把看到的状态、动作都存下来当“原料”。这些轨迹不带任何任务标签,保证提炼出的知识足够通用。接下来把轨迹描述交给GPT,让它帮忙点评:“哪些行为更像是合理、聪明的?” 具体有三种提炼套路,分别对应三条技术路线(论文称BK-CODE、BK-PREF、BK-GOAL)。
BK-CODE让大模型直接写Python奖励函数,研究者迭代运行、再把结果反馈给GPT-4 改进,直到输出一段能稳定评价“好状态”与“坏状态”的代码。
BK-PREF把两段轨迹丢给GPT-4做“二选一”,随后用基于Bradley–Terry模型的偏好学习方法把这些偏好信息转化为奖励信号。
BK-GOAL请GPT-4根据轨迹列出可能的子目标(如“合成木镐”、“避开熔岩”),并在训练时计算当前状态与这些目标的相似度。
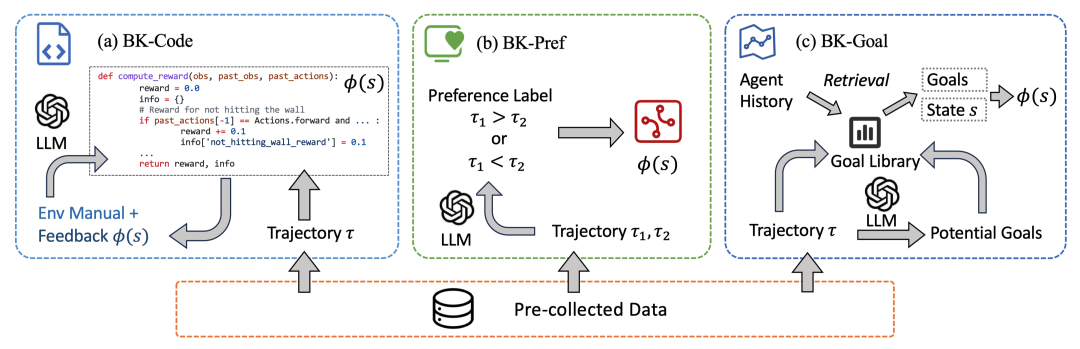
三条路线的共同点是:最后都会得到一个势函数[数学公式],训练时额外加上形如[数学公式]的潜在奖励。根据经典理论,这样做不会改变原任务最优策略,而合理的势函数选择却能起到加快收敛的效果。最后,作者基于经典的PPO方法,在下游任务上加入奖励重塑(reward shaping)进行RL训练。
效果到底有多快?
论文在Minigrid和Crafter两个不同类型环境中进行了大量实验,验证了引入背景知识的奖励塑形对样本效率的提升效果。
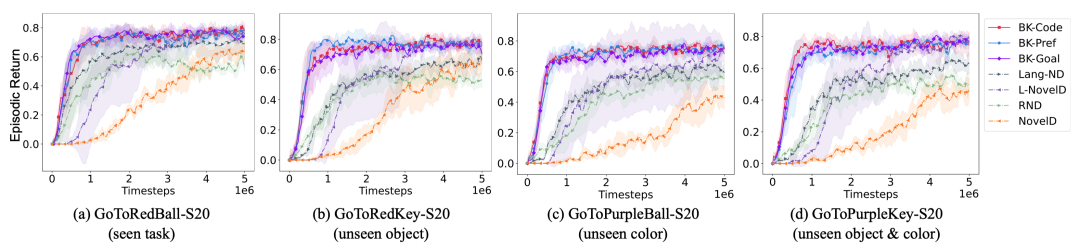
在Minigrid的四个任务中(包括有的新目标物体类型和颜色是知识提取时未出现过的),三种变体均全面超越了现有的探索增强基线方法和基于语言的探索方法(如RND、NovelD等)。即使对于LLM从未“见过”的新任务类型,利用背景知识的智能体依然展现出明显优势,证明提取的知识确实具有任务无关性,可以泛化到新的目标。更难能可贵的是,提炼背景知识只需一次LLM调用,后续训练零 LLM调用成本。
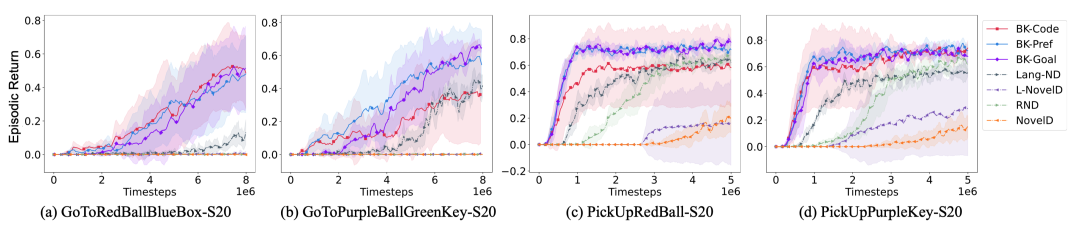
更令人惊喜的是,背景知识对新任务和更大规模环境的泛化能力也得到了验证。作者让智能体在Minigrid中只从简单的“Goto”类任务提取知识(即导航去找单一目标物品),然后测试在更加复杂的新任务上,例如需要按顺序找两个目标(Goto-seq)或找到目标后执行拾起动作(Pickup)。
结果显示,无需重新调用LLM,之前提炼的知识直接用于这些新任务,依然大幅提升了学习效率:相比之下,原有基线在这些更难任务上几乎学不到任何东西,而有背景知识加持的智能体很快学会了解决任务。
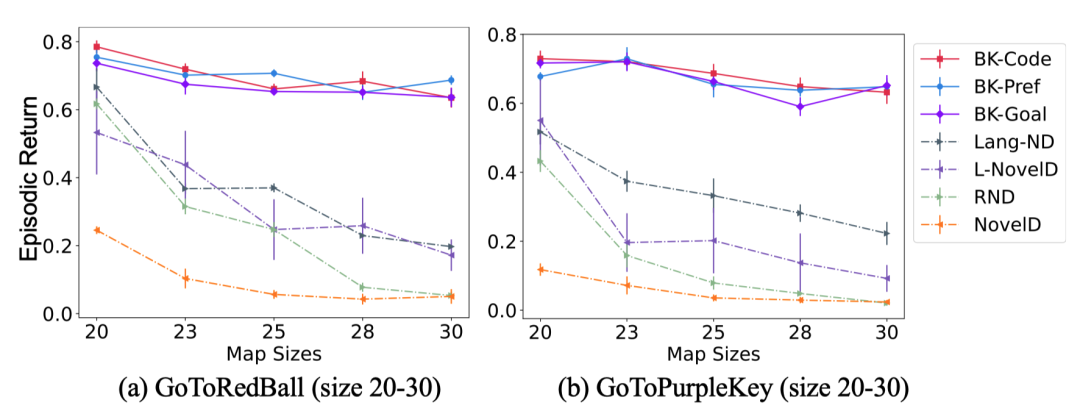
另外,当将Minigrid的地图规模从20×20扩大到30×30时,含背景知识的智能体依旧保持了高采样效率,而基线方法的性能随着地图变大急剧下降。这说明预先获取的环境知识具有良好的可扩展性,能帮助智能体应对更复杂、更大的环境。
论文链接:https://arxiv.org/abs/2407.03964
项目代码:https://github.com/mansicer/background-knowledge-rl
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
科技前沿进展每日见
启盈优配提示:文章来自网络,不代表本站观点。



沪深京行情 实时轮播
热点资讯




